Proyecto_IV
Proyecto para la asignatura Infraestructura Virtual (UGR)
Duckpiler assistant
El proyecto a desarrollar será un servicio que proporcione un pdf que sea el resultado de una compilación de un fichero LaTeX o Markdown.
¿Por qué?
En numerosas ocasiones, trabajando en el repositorio de los apuntes de libreim se ha dado el caso de que algún compañero estaba intentando estudiar pero se encontraba desde algún dispositivo móvil, desde algún sistema operativo inapropiado o simplemente no tenía herramientas de compilación a mano. Por lo que se pensó hacer algún tipo de compilador automático que resuelva este problema.
Añadiendo Integración Continua
Herramientas utilizadas
Para llevar a cabo los tests se empezó usando (dada la simplicidad de los tests actuales) el módulo assert, que se encuentra incluído en node. Pero posteriormente se observó un beneficio por utilizar chai para realizar tests más complejos.
Para ejecutar los tests se ha usado Mocha, pues es un framework bastante extendido y cómodo que nos describe el resultado de la ejecución de los tests junto al tiempo transcurrido (lo cual puede ayudar a la hora de establecer algún benchmark para probar la aplicación).
Para gestionar la integración continua se ha utilizado travis, principalmente por su integración con github y su facilidad de uso.
Para gestionar el despliegue se ha realizado con una máquina virtual en azure, aprovechando el registro que hicimos en los ejercicios del tema introductorio y las suscripciones proporcionadas por el profesor de la asignatura (aunque también existen otras alternativas como Heroku, que también es popular en el uso de node.js o zeit)
La configuración que usará travis para realizar las pruebas de
integración continua se debe indicar en el fichero .travis.yml.
En el cual indicaremos qué lenguaje estamos usando, su versión, las
dependencias necesarias a instalar y el script a usar para probar los
tests:
language: node_js
node_js:
- "8.12"
before_install:
- npm install --save-dev mocha
- npm install mocha
script: npm test
Desplegando
Desplegando en Heroku
Se ha elegido Heroku como PaaS para desplegar la aplicación,
principalmente por ser una de las mejores herramientas gratuitas que
se integran bien con node.js. Proporciona otras
facilidades como la sencillez con la que se pueden desplegar
aplicaciones con simplemente hacer push al repositorio de Heroku (de
hecho, con la configuración adecuada se puede gestionar el push
automático con cada push al repositorio de github). Permite
seleccionar la región del servidor en la que estará tu aplicación y
permite “dormir” o desactivar las aplicaciones cuando estén un tiempo
sin ser usadas para permitir ahorrar recursos.
Para crear la app primero debemos pedirle a heroku que la cree en nuestra región. En nuestro repositorio ejecutaríamos:
heroku apps:create --region eu
Esto nos dará una aplicación con un nombre aleatorio. Así que podemos renombrarlo al nombre que queremos.
heroku apps:rename --app nombre-aleatorio-69349 genuine-duckpiler
Y es importante destacar que esto implica que hay que cambiar la url del remote de heroku, pues en caso contrario intentaríamos publicar en un repo de heroku que ya no existe.
git remote set-url heroku
https://git.heroku.com/genuine-duckpiler.git
Antes de publicarlo necesitamos añadir a nuestro proyecto un archivo
Procfile que indique cómo se debe lanzar la aplicación. Este fichero
simplemente tendrá web: sudo npm start. web: implica que es una
aplicación web y sudo npm start indica cómo se ha de ejecutar esta
aplicación web. Y para publicarlo tendríamos que hacer push a dicho
repositorio.
git push heroku master
Si queremos desplegar la aplicación como un contenedor de docker
tenemos que indicarlo en el archivo heroku.yml.
build:
docker:
web: Dockerfile
Con esto tendríamos nuestra aplicación desplegada.
Despliegue aquí: https://genuine-duckpiler.herokuapp.com/
Despliegue automático desde Github
Cuando estamos trabajando es posible que queramos realizar
“simultáneamente” el despliegue en Github y en Heroku. Así ahorrarnos
tener que hacer push al repo de Github y de Heroku por separado.
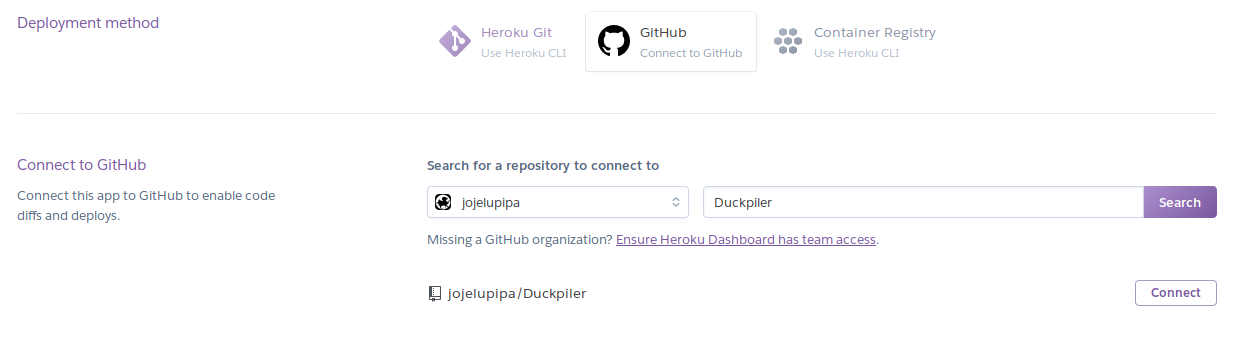
Por suerte podemos encontrar un modo de automatizar este proceso, en nuestro caso configuramos desde Heroku el despliegue autorizando el acceso al repo de github. Primero tenemos que conectar la aplicación.
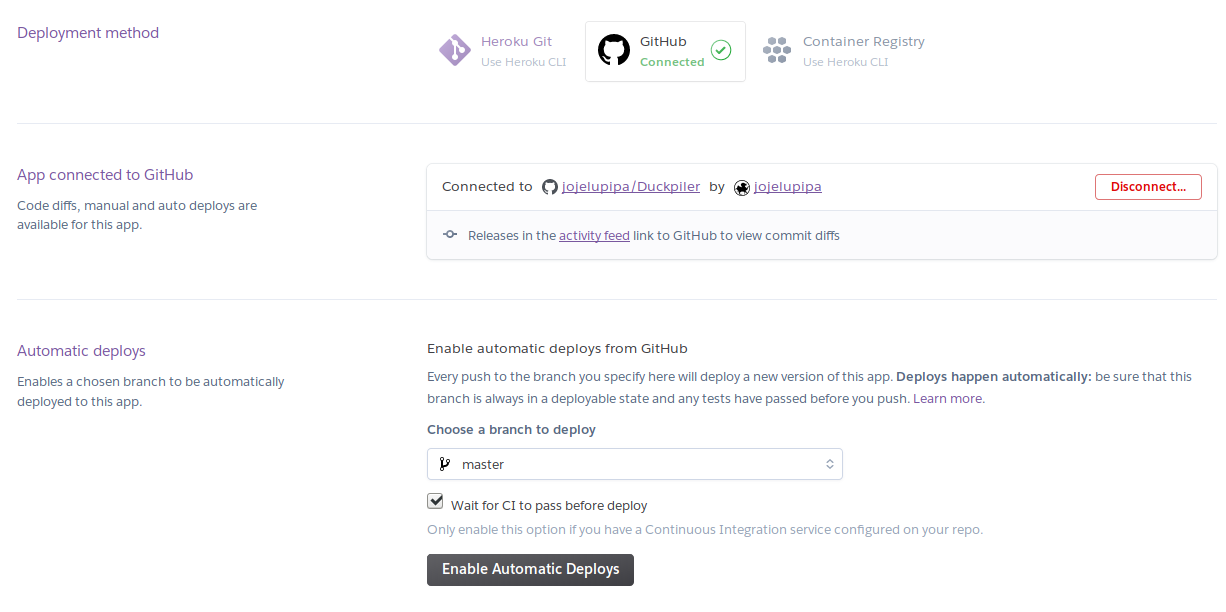
Y para confirmar simplemente activamos las opciones de despliegue automático, que es compatible con CI, para que solo se despliegue en caso de haber pasado los tests de Integración Continua.
Despliegue con Docker en Zeit
Hemos creado en DockerHub un repositorio para nuestro proyecto (al cual se publicará automáticamente al hacer push a Github con un webhook).
Y posteriormente lo hemos desplegado en Zeit con la orden now, que
se ejecuta en función del contenido del archivo now.json.
Para el archivo now.json hemos tenido que configurar algunas cosas:
{
"type":"docker", // Indica que estamos desplegando un contenedor de Docker
"version": 1,
"features": { // Previene de la restricción de tamaño
"cloud": "v1"
}
}
Contenedor: https://duckpiler-gxwwizygwr.now.sh/
Para el contenedor hemos utilizado un fichero Dockerfile que nos ha permitido configurar cómo se construye dicho contenedor y qué comando hay que usar para ejecutar nuestra aplicación. Y para el despliegue en Zeit hemos proporcionado un archivo de configuración para que se pueda desplegar el contenedor de Docker.
Es destacable acerca del Dockerfile la siguiente configuración:
# Esta es la imagen desde la que queremos construir
FROM node:8.15.0-jessie
# El directorio (arbitrario) sobre el cual trabajaremos
WORKDIR /usr/src/app
# La instalación de dependencias de npm
COPY package.json ./
RUN npm install
# La copia del código que queramos ejecutar en el servidor
COPY ./src ./src
# La activación de la escucha en el puerto que de nuestro servicio
EXPOSE 80
# La instalación de los paquetes que se requieran
RUN apt-get update
RUN apt-get install pandoc -y
# El comando que se utilizará para lanzar el contenedor y desplegar la app
CMD [ "npm", "start" ]
Replicación del entorno
¿Quieres probar el servicio en un entorno testeado?
Bien sea para desarrollar o para probarlo por ti mismo puedes hacer
uso de vagrant para desplegar una
máquina debidamente provisionada
con chef. Simplemente tienes que usar
vagrant up ya puedes disponer de una máquina con todo lo necesario.
Provisionamiento con chef
Chef-solo es la herramienta que nos va a asegurar que la máquina que despleguemos va a tener todos los paquetes y herramientas necesarias para que nuestra aplicación funcione debidamente.
Chef se basa en instalar “recetas” (recipes). El ejemplo más simple de esto puede ser nuestro archivo git/default.rb, cuyo contenido es el siguiente:
package 'git'
Con lo cual instalará el paquete git allá donde se encuentre instalado chef-solo disponible para ser usado.
Las recetas se agrupan en torno a “cookbooks”. “Libros de cocina”,
el directorio que recoge las distintas recetas de nuestro proyecto a
cocinar. Y será necesario indicarle a nuestro archivo de
configuración cómo se llamará este directorio si no tomará
“cookbooks” por omisión (chef.cookbooks_path = "provision").
Además hay otro elemento importante en chef, y estos son los roles, una manera de definir patrones de trabajo o un conjunto de acciones a realizar. Esto nos permite proporcionarle a nuestra máquina una run list, el conjunto de recetas que tendrá que instalar. De este modo sólo tendríamos que proporcionarle en el vagrantfile la ruta y el role a añadir.
El role tiene esta estructura:
{
"name": "vagrant",
"chef_type": "role",
"json_class": "Chef::Role",
"description": "Vagrant instance, responsible for deploying a VM",
"default_attributes": {},
"run_list": [
"recipe[git]",
"recipe[npm]",
"recipe[nodejs]"
]
}
Donde se encuentran los metadatos que describen el role y lo más relevante: La run list, que indica las recetas que se han de instalar.
Es necesario destacar que es posible tener más de una receta por
programa. Es decir, que podríamos no solamente tener nuestro archivo
git/default.rb que instale el paquete, sino que también podríamos
tener otra receta para actualizarlo, a la que podríamos llamar
git/update.rb. Si quisieramos lanzar esa receta en nuestra run
list sería necesario indicar qué receta exactamente queremos instalar
(Lo haríamos con recipe[git::update]. Por omisión toma
recipe[receta::default].).
Configuración entorno con Azure
Esta configuración se ha hecho para desplegar una máquina virtual de azure con nuestra herramienta Vagrant. Para ello es necesario utilizar un archivo (programa escrito en ruby) Vagrantfile:
# En primer tenemos que elegir la configuración de Vagrant. Algunas
funcionalidades no están disponibles para otras versiones distinta a
la usada ("2")
Vagrant.configure("2") do |config|
## Configuramos las máquinas virtuales de azure
### Elegimos el nombre de la vagrantbox localmente
instalada/disponible en HasiCorp's Vagrant Cloud que
usaremos levantar la máquina
config.vm.box = "azure"
### Proporcionaremos la ruta de nuestra clave privada para
conectarnos via SSH con nuestra máquina
config.ssh.private_key_path = '~/.ssh/id_rsa'
## A continuación se procede a la configuración exclusiva de azure
config.vm.provider :azure do |azure, override|
### Elegimos el nombre de la máquina virtual, en lugar de utilizar
uno aleatorio
azure.vm_name = "duckpiler"
### Establecemos el nombre del grupo de recursos a usar. Nos puede
evitar crear uno con un nombre distinto en cada despliegue, pero
puede producir errores y demoras si se están realizando numerosos
despliegues (se puede comentar esta línea si esto supone un problema)
azure.resource_group_name = "duckpiler_resource_group"
### Podemos elegir una ubicación adecuada para nuestras VM para
mejorar el rendimiento
azure.location = "westeurope"
### Exponemos el puerto en el que nuestra aplicación escuchará
azure.tcp_endpoints = "80"
### También es necesario para usar azure configurar un conjunto de
claves e ID's cuya forma más segura de proporcionar es mediante
variables de entorno
azure.tenant_id = ENV['AZURE_TENANT_ID']
azure.client_id = ENV['AZURE_CLIENT_ID']
azure.client_secret = ENV['AZURE_CLIENT_SECRET']
azure.subscription_id = ENV['AZURE_SUBSCRIPTION_ID']
end
## Para el provisionamiento configuramos chef
config.vm.provision "chef_solo" do |chef|
### Proporcionamos la ruta a los cookbooks
chef.cookbooks_path = "provision"
### Ruta a los roles
chef.roles_path = "provision/roles"
### Roles a añadir
chef.add_role("vagrant")
end
Replicación del entorno sin Azure
Si quieres conseguir una máquina virtual local que esté igualmente configurada puedes ignorar las especificaciones del Vagrantfile para Azure y usar otro genérico como este:
Vagrant.configure("2") do |config|
config.vm.box = "nombre_maquina_virtual"
# Redirigir el puerto del servicio a tu puerto 5000 (puede elegirse otro)
config.vm.network "forwarded_port", guest: 5000, host: 80
# Install with chef
config.vm.provision "chef_solo" do |chef|
chef.add_recipe "emacs"
chef.add_recipe "git"
end
end
Esto, tras descargar alguna vagrantbox y
sustituir el valor de config.vm.box por el que corresponda
permitiría preparar un entorno debidamente provisionado con vagrant
up. Lo que dejaría lista la máquina para trabajar con ella con
vagrant ssh (una conexión ssh “automatizada” a esta máquina).
Despliegue de la aplicación en entorno remoto
Para desplegar la aplicación en este nuevo entorno hemos usado flightplan (aprovechando que estamos usando nodejs).
Nuestros planes de vuelo
Con este conjunto de planes podemos:
Desplegar de cero la aplicación y tenerla de servicio
fly deployTo:azure --flightplan despliegue/flightplan.js
Detener con otro plan de vuelo la ejecución del servicio
fly stop:azure --flightplan despliegue/flightplan.js
Reanudar el servicio
fly run:azure --flightplan despliegue/flightplan.js
Borrar el repositorio
fly deleteAll:azure --flightplan despliegue/flightplan.js
En definitiva cualquiera puede coger este proyecto y desplegarlo con dos sencillas órdenes:
vagrant up
fly deployTo:azure --flightplan despliegue/flightplan.js
¿Cómo funcionan?
Flightplan, como se puede ver en su documentación es una biblioteca de nodejs, la cual nos permite ejecutar secuencias de comandos shell en hosts locales y remotos. Osea, que para usarlo tendremos que escribir un archivo en javascript. Por lo cual, para usarlo lo primero que tenemos que hacer es describir nuestro target:
plan.target('azure', {
host: 'duckpiler.westeurope.cloudapp.azure.com',
username: 'vagrant',
agent: process.env.SSH_AUTH_SOCK
});
Donde nombramos nuestro target “azure”, e indicamos mediante un objeto javascript el resto de propiedades que nos interesen. En nuestro caso el host (DNS proporcionado por azure), el usuario (“vagrant” al estar por defecto usando vagrant) y el medio de autenticación.
A continuación procedemos a definir los planes de vuelo:
plan.remote(
'deployTo',
remote => {
remote.log('Let\'s run Duckpiler');
// Cloning repository
remote.exec('git clone https://github.com/jojelupipa/Duckpiler.git');
// Installing dependencies
remote.exec('npm install --prefix Duckpiler');
// Launching service
remote.exec('sudo npm start --prefix Duckpiler');
});
Con plan.remote(name, fallback_func); podemos ejecutar una secuencia de
órdenes en nuestro host remoto. Entre las cuales se encuentran
log(), para imprimir por pantalla, exec() para ejecutar órdenes
(la más esencial), sudo() lo propio, pero como superusuario (Hay
otras predefinidas como echo, ls, rm… que se usan en otros planes
cuya funcionalidad es intuitiva y se pueden consultar en su
documentación).
Si quisieramos realizar acciones en el host local se puede utilizar
plan.local(fallback_func). Esto puede ser útil para realizar
transferencias de archivos local.transfer(files, remote_path). En
nuestro caso esto no ha sido necesario pues hemos provisionado las
máquinas para que puedan descargarse el repositorio con git.
Normalmente, cuando está desplegada se encuentra la aplicación en este dominio.
Este dominio es proporcionado por azure a la hora de publicar una máquina virtual con un nombre en una localización determinada.